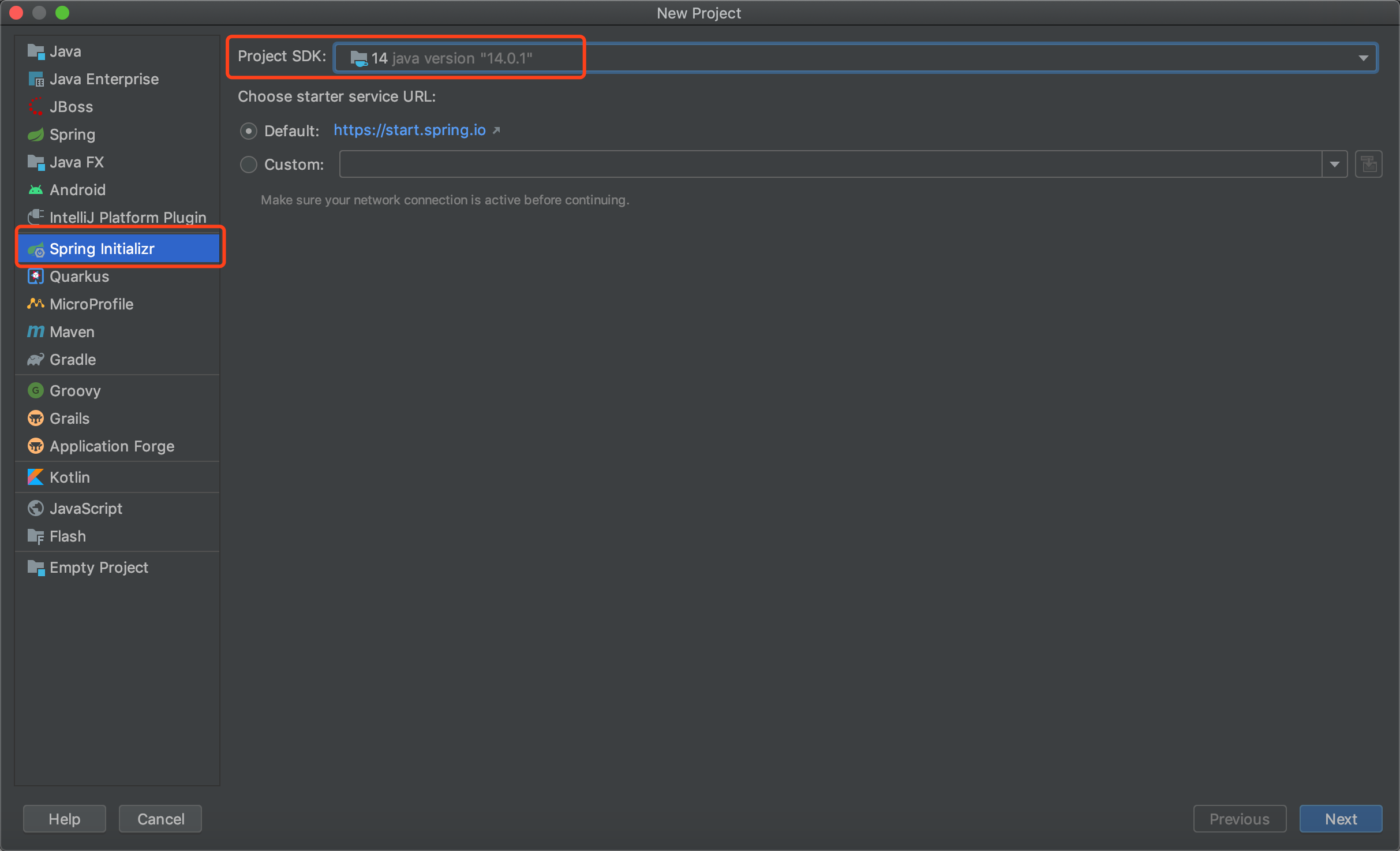
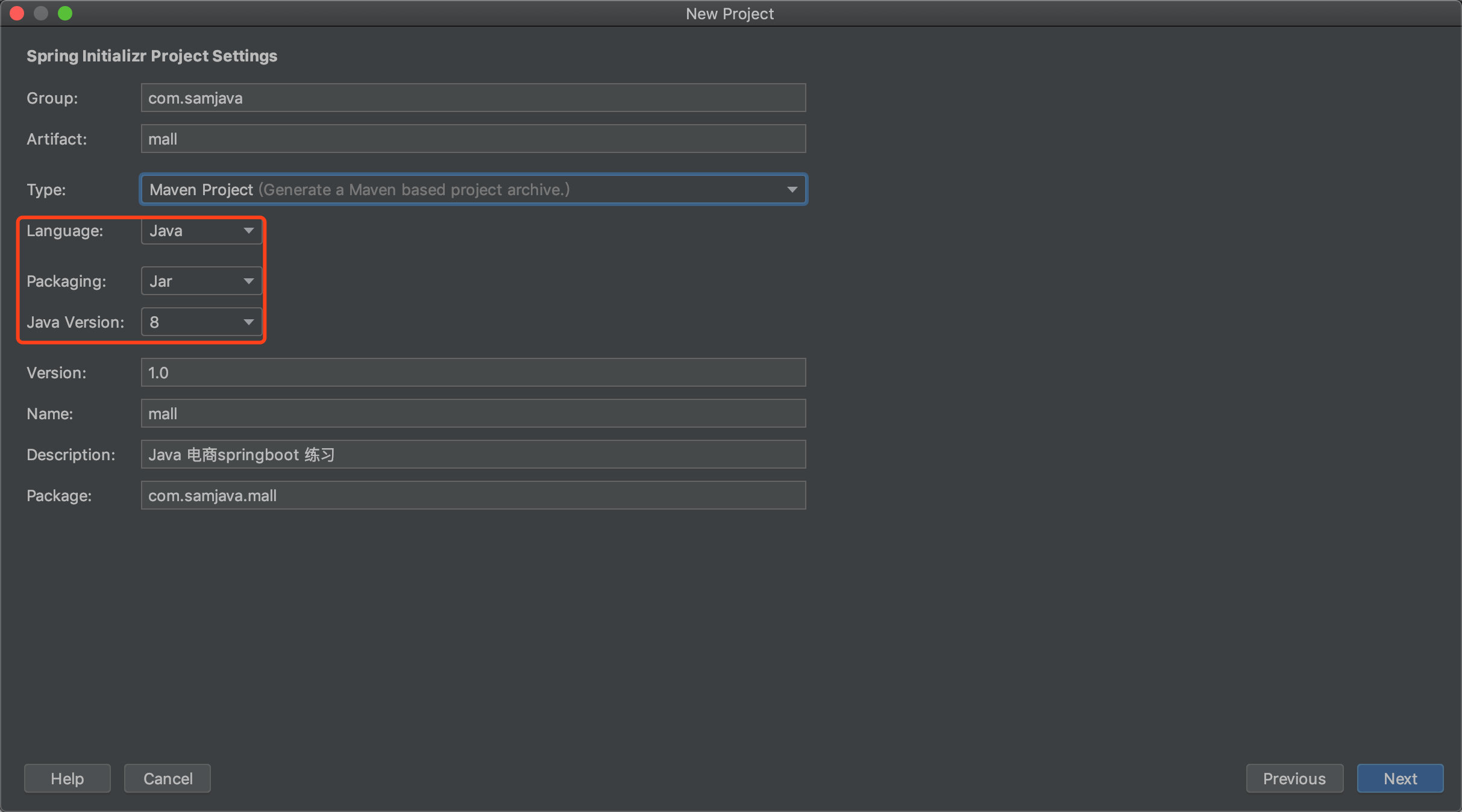
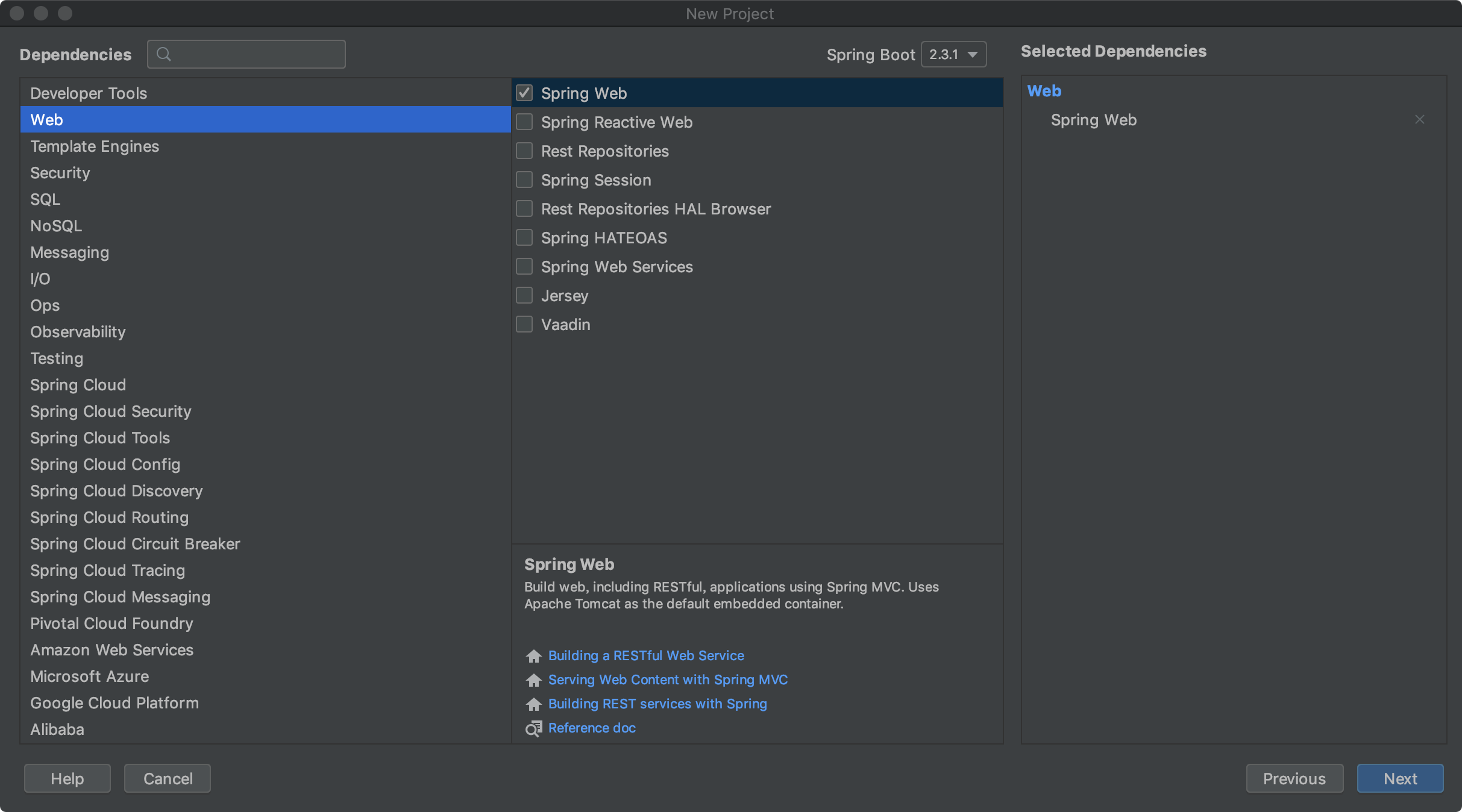
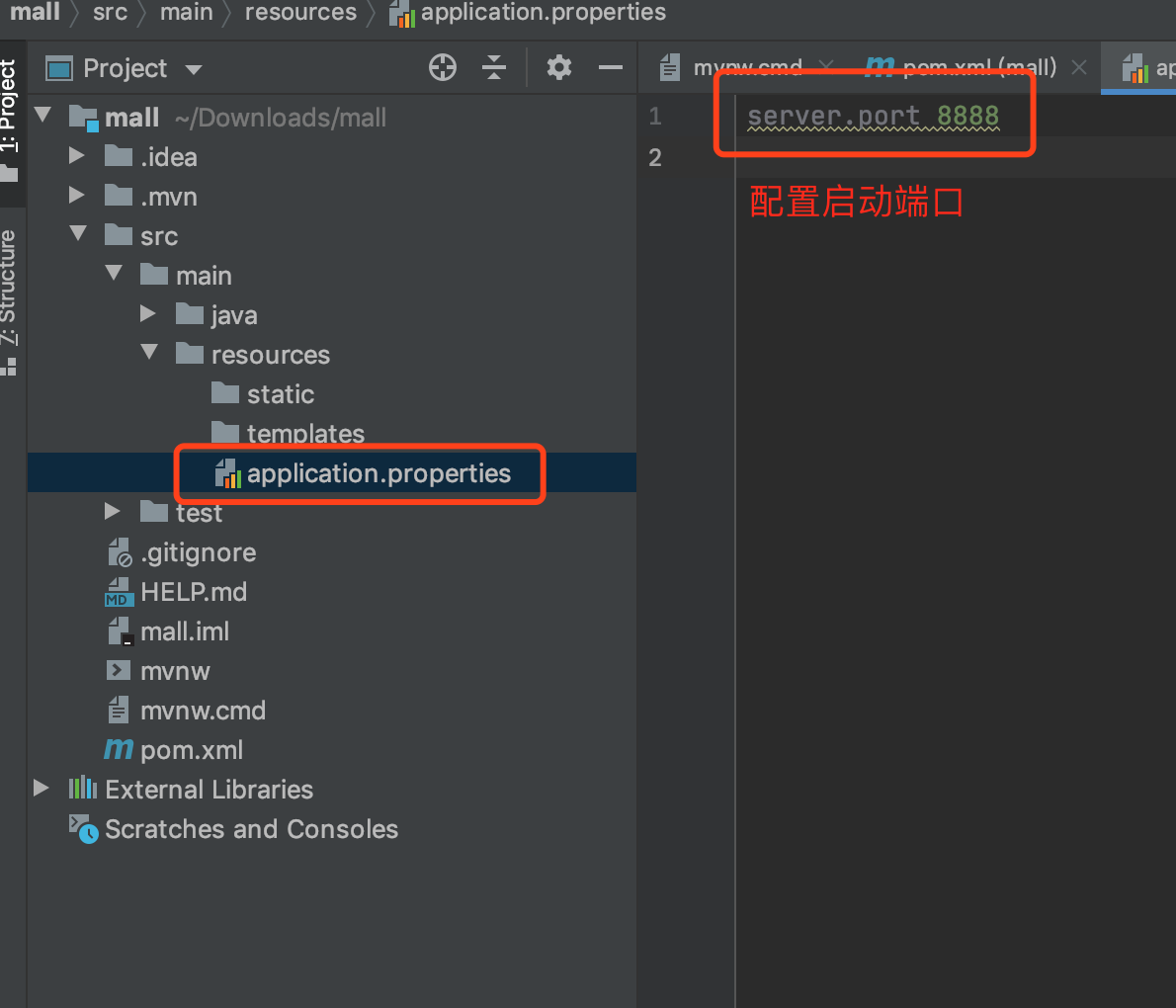
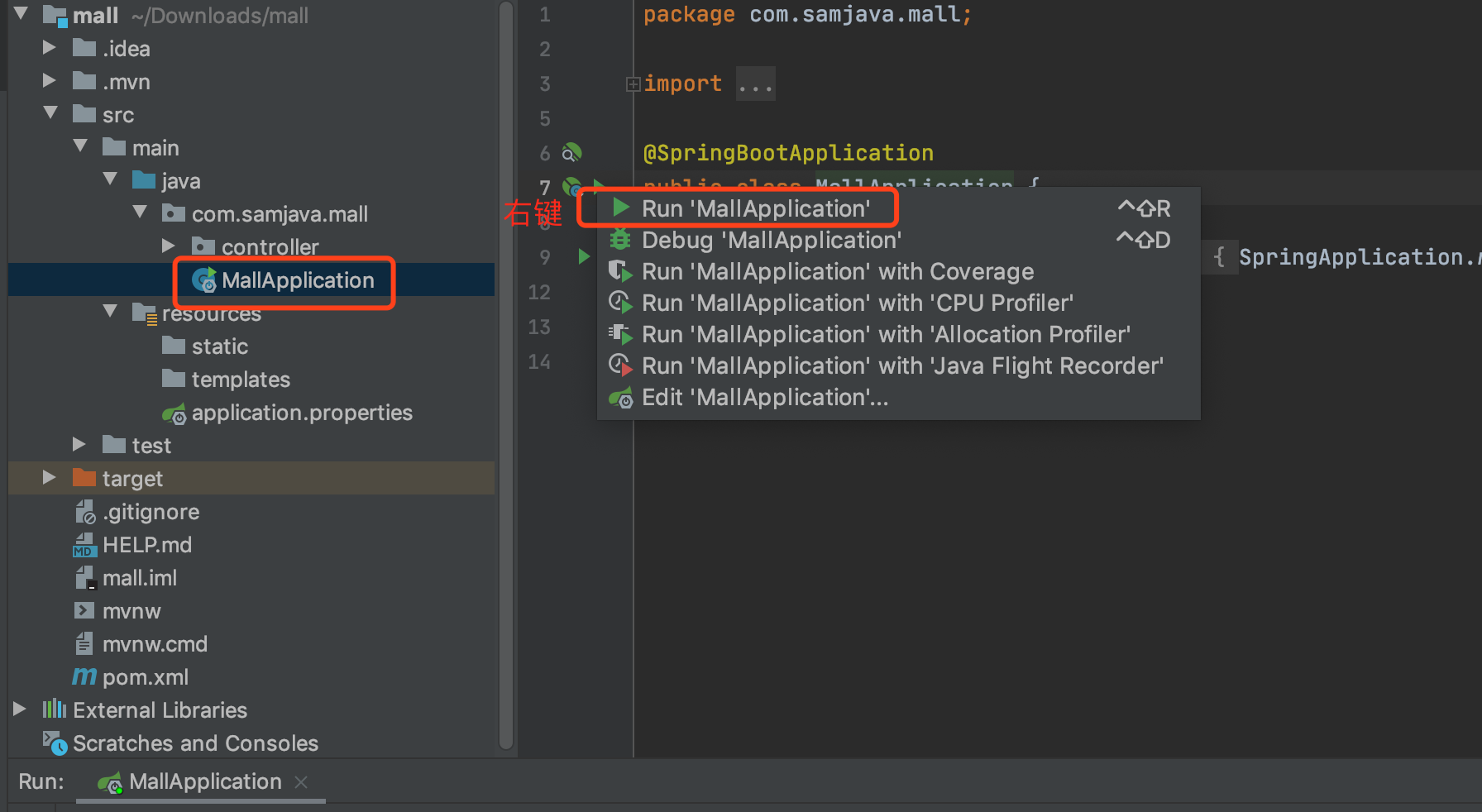
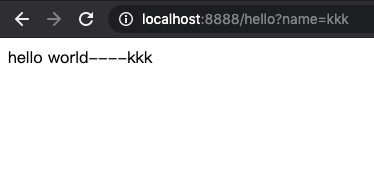
安装插件
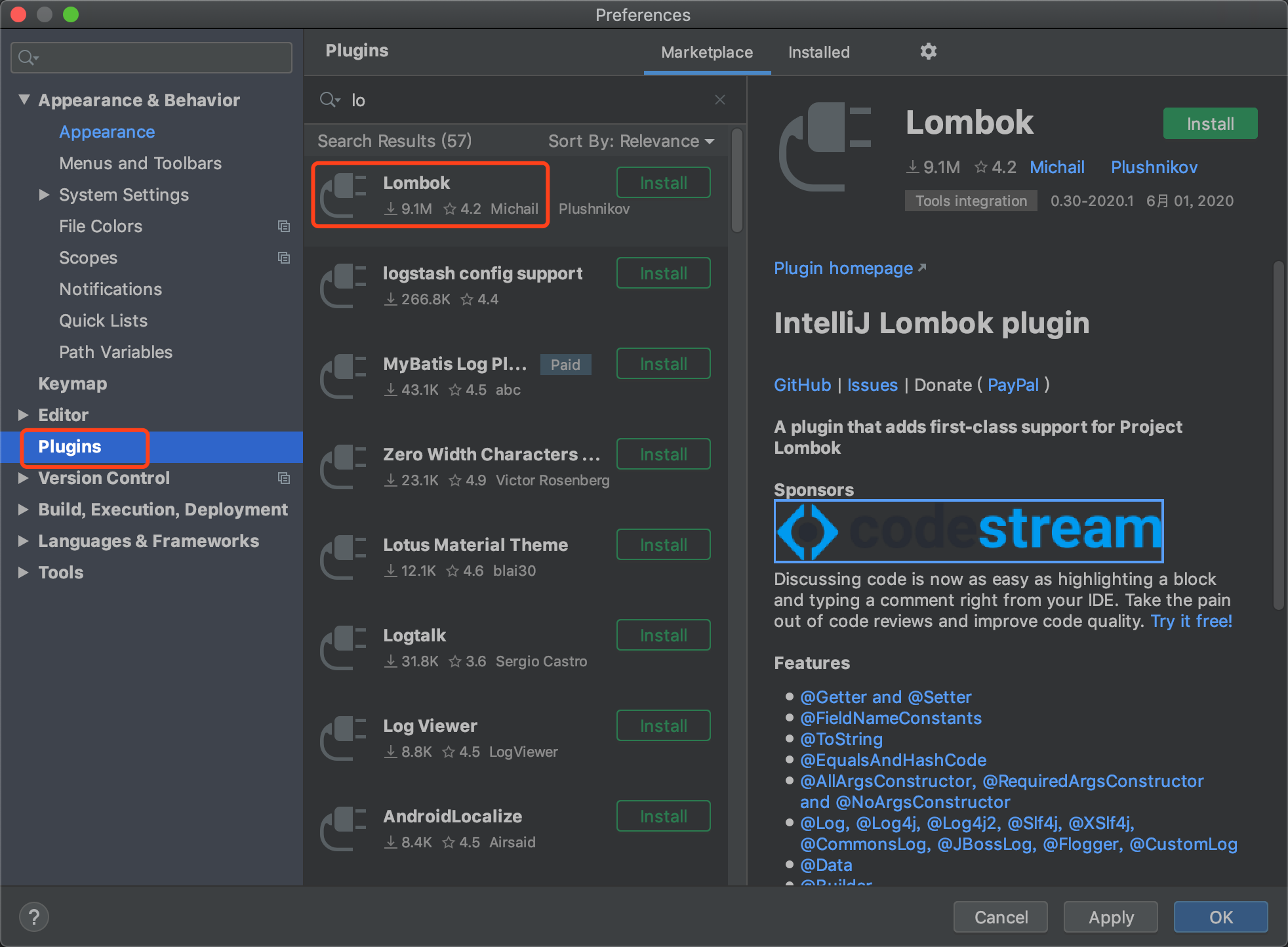
配置插件
1 | <dependency> |
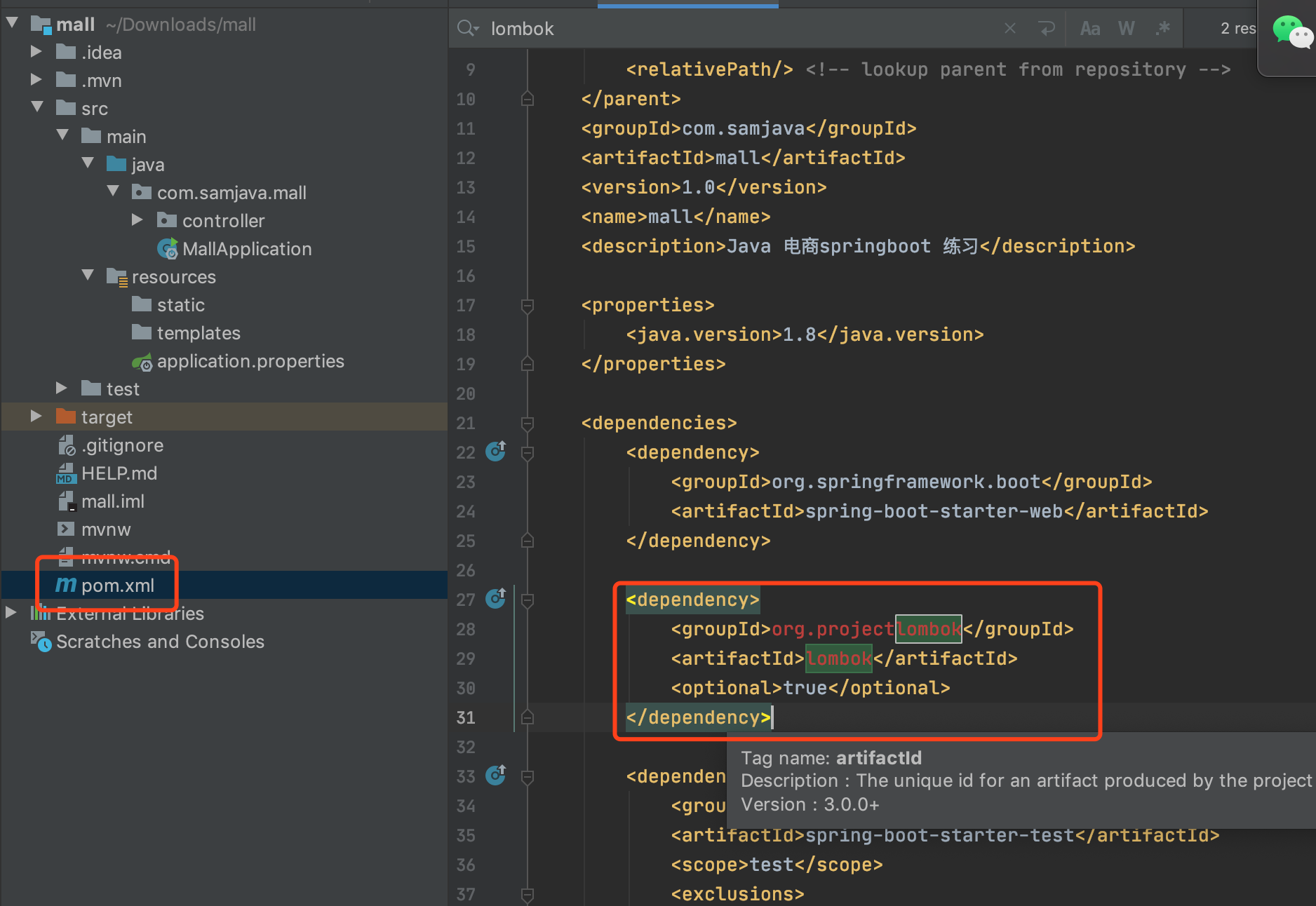
在Spring Boot项目里面不需要加入版本号,spring Boot父项目会代为管理。如果是其他项目,请自行添加版本号!
使用
- Data
1 | package com.samjava.mall.model; |
- Slf4j
- Builder
- AllArgsConstructor
1 | <dependency> |
在Spring Boot项目里面不需要加入版本号,spring Boot父项目会代为管理。如果是其他项目,请自行添加版本号!
1 | package com.samjava.mall.model; |
1 | #安装maven |
将参数传递给方法有两种常见的方式,一种是“值传递”,一种是“引用传递”。C 语言本身只支持值传递,它的衍生品 C++ 既支持值传递,也支持引用传递,而 Java 只支持值传递。
首先,我们必须要搞清楚,到底什么是值传递,什么是引用传递,否则,讨论 Java 到底是值传递还是引用传递就显得毫无意义。
当一个参数按照值的方式在两个方法之间传递时,调用者和被调用者其实是用的两个不同的变量——被调用者中的变量(原始值)是调用者中变量的一份拷贝,对它们当中的任何一个变量修改都不会影响到另外一个变量。
而当一个参数按照引用传递的方式在两个方法之间传递时,调用者和被调用者其实用的是同一个变量,当该变量被修改时,双方都是可见的。
Java 程序员之所以容易搞混值传递和引用传递,主要是因为 Java 有两种数据类型,一种是基本类型,比如说 int,另外一种是引用类型,比如说 String。
基本类型的变量存储的都是实际的值,而引用类型的变量存储的是对象的引用——指向了对象在内存中的地址。值和引用存储在 stack(栈)中,而对象存储在 heap(堆)中。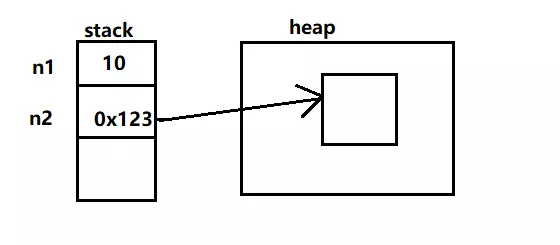
之所以有这个区别,是因为:
众所周知,Java 有 8 种基本数据类型,分别是 int、long、byte、short、float、double 、char 和 boolean。它们的值直接存储在栈中,每当作为参数传递时,都会将原始值(实参)复制一份新的出来,给形参用。形参将会在被调用方法结束时从栈中清除。
来看下面这段代码:
1 | public class PrimitiveTypeDemo { |
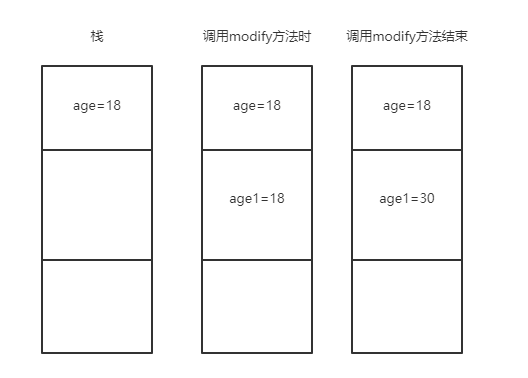
1)main 方法中的 age 是基本类型,所以它的值 18 直接存储在栈中。
2)调用 modify() 方法的时候,将为实参 age 创建一个副本(形参 age1),它的值也为 18,不过是在栈中的其他位置。
3)对形参 age 的任何修改都只会影响它自身而不会影响实参。
来看一段创建引用类型变量的代码:
Writer writer = new Writer(18, "沉默王二");
writer 是对象吗?还是对象的引用?为了搞清楚这个问题,我们可以把上面的代码拆分为两行代码:
1 | Writer writer; |
假如 writer 是对象的话,就不需要通过 new 关键字创建对象了,对吧?那也就是说,writer 并不是对象,在“=”操作符执行之前,它仅仅是一个变量。那谁是对象呢?new Writer(18, "沉默王二"),它是对象,存储于堆中;然后,“=”操作符将对象的引用赋值给了 writer 变量,于是 writer 此时应该叫对象引用,它存储在栈中,保存了对象在堆中的地址。
每当引用类型作为参数传递时,都会创建一个对象引用(实参)的副本(形参),该形参保存的地址和实参一样。
来看下面这段代码:
1 | public class ReferenceTypeDemo { |
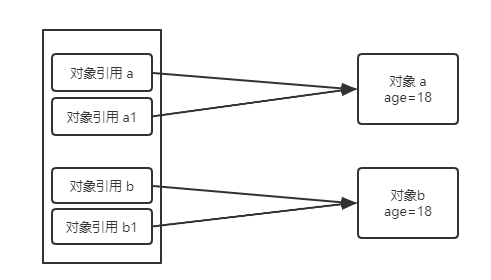
1)在调用 modify() 方法之前,实参 a 和 b 指向的对象是不一样的,尽管 age 都为 18。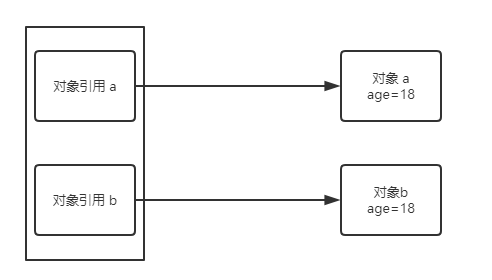
2)在调用 modify() 方法时,实参 a 和 b 都在栈中创建了一个新的副本,分别是 a1 和 b1,但指向的对象是一致的(a 和 a1 指向对象 a,b 和 b1 指向对象 b)。
3)在 modify() 方法中,修改了形参 a1 的 age 为 30,意味着对象 a 的 age 从 18 变成了 30,而实参 a 指向的也是对象 a,所以 a 的 age 也变成了 30;形参 b1 指向了一个新的对象,随后 b1 的 age 被修改为 30。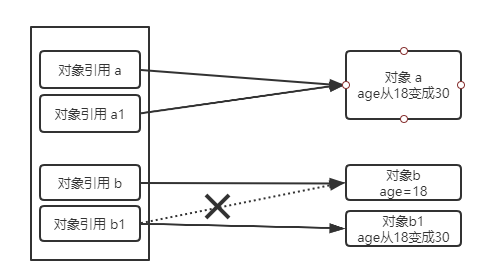
修改 a1 的 age,意味着同时修改了 a 的 age,因为它们指向的对象是一个;修改 b1 的 age,对 b 却没有影响,因为它们指向的对象是两个。
程序输出的结果如下所示:
1 | 30 |
果然和我们的分析是吻合的。
配置
1 | <dependency> |
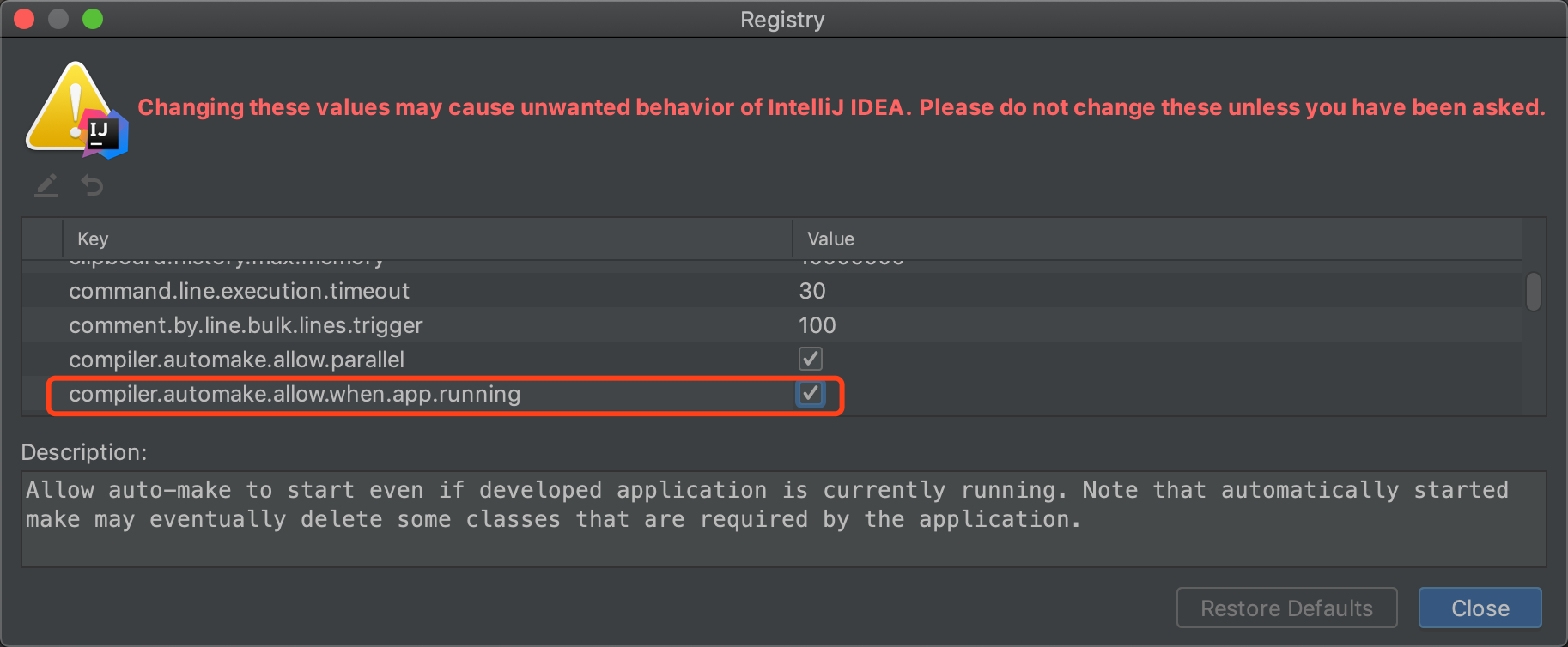
Shift+Ctrl+Alt+/,选择 Registry ,选中打勾 compiler.automake.allow.when.app.running 。
Codota 代码自动补全。Auto filling Java call arguments 自动填充函数参数。GsonFormat 快速的将JSON转换为实体类。
插件安装好之后,先定义一个空的实体类(只有类名和花括号),使用快捷键Alt + S调出代码生成配置页面Rainbow Brackets 括号颜色匹配。Maven Helper 直接打开pom文件,即可查看依赖数,还能自动分析是否存在jar包冲突。
尽管继承可以让我们重用现有代码,但有时处于某些原因,我们确实需要对可扩展性进行限制,final 关键字可以帮助我们做到这一点。
01、final 类
如果一个类使用了 final 关键字修饰,那么它就无法被继承。如果小伙伴们细心观察的话,Java 就有不少 final 类,比如说最常见的 String 类。
1 | public final class String |
为什么 String 类要设计成 final 的呢?原因大致有以下三个:
为了实现字符串常量池
为了线程安全
为了 HashCode 的不可变性
更详细的原因,可以查看我之前写的一篇文章。
任何尝试从 final 类继承的行为将会引发编译错误,为了验证这一点,我们来看下面这个例子,Writer 类是 final 的。
1 | public final class Writer { |
尝试去继承它,编译器会提示以下错误,Writer 类是 final 的,无法继承。
不过,类是 final 的,并不意味着该类的对象是不可变的。
1 | Writer writer = new Writer(); |
Writer 的 name 字段的默认值是 null,但可以通过 settter 方法将其更改为“沉默王二”。也就是说,如果一个类只是 final 的,那么它并不是不可变的全部条件。
如果,你想了解不可变类的全部真相,请查看我之前写的文章这次要说不明白immutable类,我就怎么地。突然发现,写系列文章真的妙啊,很多相关性的概念全部涉及到了。我真服了自己了。
把一个类设计成 final 的,有其安全方面的考虑,但不应该故意为之,因为把一个类定义成 final 的,意味着它没办法继承,假如这个类的一些方法存在一些问题的话,我们就无法通过重写的方式去修复它。
02、final 方法
被 final 修饰的方法不能被重写。如果我们在设计一个类的时候,认为某些方法不应该被重写,就应该把它设计成 final 的。
Thread 类就是一个例子,它本身不是 final 的,这意味着我们可以扩展它,但它的 isAlive() 方法是 final 的:
1 | public class Thread implements Runnable { |
需要注意的是,该方法是一个本地(native)方法,用于确认线程是否处于活跃状态。而本地方法是由操作系统决定的,因此重写该方法并不容易实现。
Actor 类有一个 final 方法 show():
1 | public class Actor { |
当我们想要重写该方法的话,就会出现编译错误:
如果一个类中的某些方法要被其他方法调用,则应考虑事被调用的方法称为 final 方法,否则,重写该方法会影响到调用方法的使用。
一个类是 final 的,和一个类不是 final,但它所有的方法都是 final 的,考虑一下,它们之间有什么区别?
我能想到的一点,就是前者不能被继承,也就是说方法无法被重写;后者呢,可以被继承,然后追加一些非 final 的方法。没毛病吧?看把我聪明的。
03、final 变量
被 final 修饰的变量无法重新赋值。换句话说,final 变量一旦初始化,就无法更改。之前被一个小伙伴问过,什么是 effective final,什么是 final,这一点,我在之前的文章也有阐述过,所以这里再贴一下地址:
http://www.itwanger.com/java/2020/02/14/java-final-effectively.html
1)final 修饰的基本数据类型
来声明一个 final 修饰的 int 类型的变量:
1 | final int age = 18; |
尝试将它修改为 30,结果编译器生气了:
2)final 修饰的引用类型
现在有一个普通的类 Pig,它有一个字段 name:
1 | public class Pig { |
在测试类中声明一个 final 修饰的 Pig 对象:
1 | final Pig pig = new Pig(); |
如果尝试将 pig 重新赋值的话,编译器同样会生气:
但我们仍然可以去修改 Pig 的字段值:
1 | final Pig pig = new Pig(); |
3)final 修饰的字段
final 修饰的字段可以分为两种,一种是 static 的,另外一种是没有 static 的,就像下面这样:
1 | public class Pig { |
非 static 的 final 字段必须有一个默认值,否则编译器将会提醒没有初始化:
static 的 final 字段也叫常量,它的名字应该为大写,可以在声明的时候初始化,也可以通过 static 代码块初始化。
4) final 修饰的参数
final 关键字还可以修饰参数,它意味着参数在方法体内不能被再修改:
1 | public class ArgFinalTest { |
如果尝试去修改它的话,编译器会提示以下错误:
开门见山地说吧,enum(枚举)是 Java 1.5 时引入的关键字,它表示一种特殊类型的类,默认继承自 java.lang.Enum。
为了证明这一点,我们来新建一个枚举 PlayerType:
1 | public enum PlayerType { |
两个关键字带一个类名,还有大括号,以及三个大写的单词,但没看到继承 Enum 类啊?别着急,心急吃不了热豆腐啊。使用 JAD 查看一下反编译后的字节码,就一清二楚了。
1 | public final class PlayerType extends Enum |
看到没?PlayerType 类是 final 的,并且继承自 Enum 类。这些工作我们程序员没做,编译器帮我们悄悄地做了。此外,它还附带几个有用静态方法,比如说 values() 和 valueOf(String name)。
01、内部枚举
好的,小伙伴们应该已经清楚枚举长什么样子了吧?既然枚举是一种特殊的类,那它其实是可以定义在一个类的内部的,这样它的作用域就可以限定于这个外部类中使用。
1 | public class Player { |
PlayerType 就相当于 Player 的内部类,isBasketballPlayer() 方法用来判断运动员是否是一个篮球运动员。
由于枚举是 final 的,可以确保在 Java 虚拟机中仅有一个常量对象(可以参照反编译后的静态代码块「static 关键字带大括号的那部分代码」),所以我们可以很安全地使用“==”运算符来比较两个枚举是否相等,参照 isBasketballPlayer() 方法。
那为什么不使用 equals() 方法判断呢?
1 | if(player.getType().equals(Player.PlayerType.BASKETBALL)){}; |
“==”运算符比较的时候,如果两个对象都为 null,并不会发生 NullPointerException,而 equals() 方法则会。
另外, “==”运算符会在编译时进行检查,如果两侧的类型不匹配,会提示错误,而 equals() 方法则不会。
02、枚举可用于 switch 语句
这个我在之前的一篇我去的文章中详细地说明过了,感兴趣的小伙伴可以点击链接跳转过去看一下。
1 | switch (playerType) { |
03、枚举可以有构造方法
如果枚举中需要包含更多信息的话,可以为其添加一些字段,比如下面示例中的 name,此时需要为枚举添加一个带参的构造方法,这样就可以在定义枚举时添加对应的名称了。
1 | public enum PlayerType { |
04、EnumSet
EnumSet 是一个专门针对枚举类型的 Set 接口的实现类,它是处理枚举类型数据的一把利器,非常高效(内部实现是位向量,我也搞不懂)。
因为 EnumSet 是一个抽象类,所以创建 EnumSet 时不能使用 new 关键字。不过,EnumSet 提供了很多有用的静态工厂方法:
下面的示例中使用 noneOf() 创建了一个空的 PlayerType 的 EnumSet;使用 allOf() 创建了一个包含所有 PlayerType 的 EnumSet。
1 | public class EnumSetTest { |
程序输出结果如下所示:
1 | [] |
有了 EnumSet 后,就可以使用 Set 的一些方法了:
05、EnumMap
EnumMap 是一个专门针对枚举类型的 Map 接口的实现类,它可以将枚举常量作为键来使用。EnumMap 的效率比 HashMap 还要高,可以直接通过数组下标(枚举的 ordinal 值)访问到元素。
和 EnumSet 不同,EnumMap 不是一个抽象类,所以创建 EnumMap 时可以使用 new 关键字:
1 | EnumMap<PlayerType, String> enumMap = new EnumMap<>(PlayerType.class); |
有了 EnumMap 对象后就可以使用 Map 的一些方法了:
和 HashMap 的使用方法大致相同,来看下面的例子:
1 | EnumMap<PlayerType, String> enumMap = new EnumMap<>(PlayerType.class); |
程序输出结果如下所示:
1 | {TENNIS=网球运动员, FOOTBALL=足球运动员, BASKETBALL=篮球运动员} |
06、单例
通常情况下,实现一个单例并非易事,不信,来看下面这段代码
1 | public class Singleton { |
但枚举的出现,让代码量减少到极致:
1 | public enum EasySingleton{ |
完事了,真的超级短,有没有?枚举默认实现了 Serializable 接口,因此 Java 虚拟机可以保证该类为单例,这与传统的实现方式不大相同。传统方式中,我们必须确保单例在反序列化期间不能创建任何新实例。
07、枚举可与数据库交互
我们可以配合 Mybatis 将数据库字段转换为枚举类型。现在假设有一个数据库字段 check_type 的类型如下:
check_type int(1) DEFAULT NULL COMMENT ‘检查类型(1:未通过、2:通过)’,
它对应的枚举类型为 CheckType,代码如下:
1 | public enum CheckType { |
1)CheckType 添加了构造方法,还有两个字段,key 为 int 型,text 为 String 型。
2)CheckType 中有一个public static CheckType parse(Integer index)方法,可将一个 Integer 通过 key 的匹配转化为枚举类型。
那么现在,我们可以在 Mybatis 的配置文件中使用 typeHandler 将数据库字段转化为枚举类型。
1 | public class CheckLog implements Serializable { |
1 | public class CheckTypeHandler extends BaseTypeHandler<CheckType> { |
CheckTypeHandler 的核心功能就是调用 CheckType 枚举类的 parse() 方法对数据库字段进行转换。
恕我直言,我觉得小伙伴们肯定会用 Java 枚举了,如果还不会,就过来砍我!
先来个提纲挈领(唉呀妈呀,成语区博主上线了)吧:
static 关键字可用于变量、方法、代码块和内部类,表示某个特定的成员只属于某个类本身,而不是该类的某个对象。
静态变量也叫类变量,它属于一个类,而不是这个类的对象。
1 | public class Writer { |
其中,countOfWriters 被称为静态变量,它有别于 name 和 age 这两个成员变量,因为它前面多了一个修饰符 static。
这意味着无论这个类被初始化多少次,静态变量的值都会在所有类的对象中共享。
1 | Writer w1 = new Writer("沉默王二",18); |
按照上面的逻辑,你应该能推理得出,countOfWriters 的值此时应该为 2 而不是 1。从内存的角度来看,静态变量将会存储在 Java 虚拟机中一个名叫“Metaspace”(元空间,Java 8 之后)的特定池中。
静态变量和成员变量有着很大的不同,成员变量的值属于某个对象,不同的对象之间,值是不共享的;但静态变量不是的,它可以用来统计对象的数量,因为它是共享的。就像上面例子中的 countOfWriters,创建一个对象的时候,它的值为 1,创建两个对象的时候,它的值就为 2。
简单小结一下:
1)由于静态变量属于一个类,所以不要通过对象引用来访问,而应该直接通过类名来访问;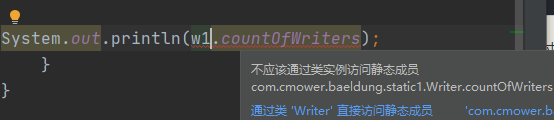
2)不需要初始化类就可以访问静态变量。
1 | public class WriterDemo { |
静态方法也叫类方法,它和静态变量类似,属于一个类,而不是这个类的对象。
1 | public static void setCountOfWriters(int countOfWriters) { |
setCountOfWriters() 就是一个静态方法,它由 static 关键字修饰。
如果你用过 java.lang.Math 类或者 Apache 的一些工具类(比如说 StringUtils)的话,对静态方法一定不会感动陌生。
Math 类的几乎所有方法都是静态的,可以直接通过类名来调用,不需要创建类的对象。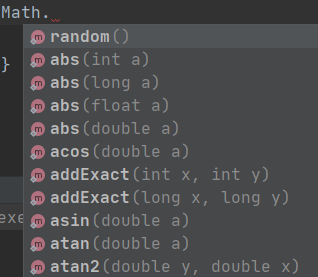
简单小结一下:
1)Java 中的静态方法在编译时解析,因为静态方法不能被重写(方法重写发生在运行时阶段,为了多态)。
2)抽象方法不能是静态的。
3)静态方法不能使用 this 和 super 关键字。
4)成员方法可以直接访问其他成员方法和成员变量。
5)成员方法也可以直接方法静态方法和静态变量。
6)静态方法可以访问所有其他静态方法和静态变量。
7)静态方法无法直接访问成员方法和成员变量。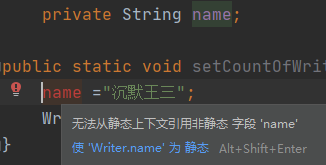
03、静态代码块
静态代码块可以用来初始化静态变量,尽管静态方法也可以在声明的时候直接初始化,但有些时候,我们需要多行代码来完成初始化。
1 | public class StaticBlockDemo { |
writes 是一个静态的 ArrayList,所以不太可能在声明的时候完成初始化,因此需要在静态代码块中完成初始化。
简单小结一下:
1)一个类可以有多个静态代码块。
2)静态代码块的解析和执行顺序和它在类中的位置保持一致。为了验证这个结论,可以在 StaticBlockDemo 类中加入空的 main 方法,执行完的结果如下所示:
第一块
第二块
04、静态内部类
Java 允许我们在一个类中声明一个内部类,它提供了一种令人信服的方式,允许我们只在一个地方使用一些变量,使代码更具有条理性和可读性。
常见的内部类有四种,成员内部类、局部内部类、匿名内部类和静态内部类,限于篇幅原因,前三种不在我们本次文章的讨论范围,以后有机会再细说。
1 | public class Singleton { |
以上这段代码是不是特别熟悉,对,这就是创建单例的一种方式,第一次加载 Singleton 类时并不会初始化 instance,只有第一次调用 getInstance() 方法时 Java 虚拟机才开始加载 SingletonHolder 并初始化 instance,这样不仅能确保线程安全也能保证 Singleton 类的唯一性。不过,创建单例更优雅的一种方式是使用枚举。
简单小结一下:
1)静态内部类不能访问外部类的所有成员变量。
2)静态内部类可以访问外部类的所有静态变量,包括私有静态变量。
3)外部类不能声明为 static。
先来看一段重写的代码吧。
1 | class LaoWang{ |
重写的两个方法名相同,方法参数的个数也相同;不过一个方法在父类中,另外一个在子类中。就好像父类 LaoWang 有一个 write() 方法(无参),方法体是写一本《基督山伯爵》;子类 XiaoWang 重写了父类的 write() 方法(无参),但方法体是写一本《茶花女》。
来写一段测试代码。
1 | public class OverridingTest { |
大家猜结果是什么?
小王写了一本《茶花女》
在上面的代码中,们声明了一个类型为 LaoWang 的变量 wang。在编译期间,编译器会检查 LaoWang 类是否包含了 write() 方法,发现 LaoWang 类有,于是编译通过。在运行期间,new 了一个 XiaoWang 对象,并将其赋值给 wang,此时 Java 虚拟机知道 wang 引用的是 XiaoWang 对象,所以调用的是子类 XiaoWang 中的 write() 方法而不是父类 LaoWang 中的 write() 方法,因此输出结果为“小王写了一本《茶花女》”。
再来看一段重载的代码吧。
1 | class LaoWang{ |
重载的两个方法名相同,但方法参数的个数不同,另外也不涉及到继承,两个方法在同一个类中。就好像类 LaoWang 有两个方法,名字都是 read(),但一个有参数(书名),另外一个没有(只能读写死的一本书)。
来写一段测试代码。
1 | public class OverloadingTest { |
这结果就不用猜了。变量 wang 的类型为 LaoWang,wang.read() 调用的是无参的 read() 方法,因此先输出“老王读了一本《Web全栈开发进阶之路》”;wang.read(“金瓶梅”) 调用的是有参的 read(bookname) 方法,因此后输出“老王读了一本《金瓶梅》”。在编译期间,编译器就知道这两个 read() 方法时不同的,因为它们的方法签名(=方法名称+方法参数)不同。
简单的来总结一下:
1)编译器无法决定调用哪个重写的方法,因为只从变量的类型上是无法做出判断的,要在运行时才能决定;但编译器可以明确地知道该调用哪个重载的方法,因为引用类型是确定的,参数个数决定了该调用哪个方法。
2)多态针对的是重写,而不是重载。
另外,我想要告诉大家的是,重写(Override)和重载(Overload)是 Java 中两个非常重要的概念,新手经常会被它们俩迷惑,因为它们俩的英文名字太像了,中文翻译也只差一个字。难,太难了。
简而言之,super 关键字就是用来访问父类的。
先来看父类:
1 | public class SuperBase { |
再来看子类:
1 | public class SuperSub extends SuperBase { |
1)super 关键字可用于访问父类的构造方法
你看,子类可以通过 super(message) 来调用父类的构造方法。现在来新建一个 SuperSub 对象,看看输出结果是什么:
SuperSub superSub = new SuperSub("子类的message");
new 关键字在调用构造方法创建子类对象的时候,会通过 super 关键字初始化父类的 message,所以此此时父类的 message 会输出“子类的message”。
2)super 关键字可以访问父类的变量
上述例子中的 SuperSub 类中就有,getParentMessage() 通过 super.message 方法父类的同名成员变量 message。
3)当方法发生重写时,super 关键字可以访问父类的同名方法
上述例子中的 SuperSub 类中就有,无参的构造方法 SuperSub() 中就使用 super.printMessage() 调用了父类的同名方法。